ChatCompletion 调优指南
1、接口功能区分
| 支持功能 | ccp | cc |
|---|---|---|
| 人设对话 | 多角色、多bot | 单一角色 |
| 生产力工具 | 支持 | 支持 |
| 示例对话 | 支持(效果更好) | 支持 |
| 返回格式限制功能(glyph格式) | 支持 | - |
| 函数调用功能 | 支持 | - |
| 插件功能 | 支持 | - |
2、接口参数区分
2.1 基础接口参数区分
2.1.1 请求体参数
| 参数位置 | 参数名称 | ccp | cc | 语义 | 功能体现 |
|---|---|---|---|---|---|
| body | use_standard_sse | - | 支持 | 是否使用标准SSE格式,设置为true时,流式返回的结果将以两个换行为分隔符。只有在stream设置为true时,此参数才会生效。 | |
| beam_width | - | 支持 | 生成多少个结果;不设置默认为1,最大不超过4。由于beam_width生成多个结果,会消耗更多token。 | ||
| prompt | - | 支持 | 对话背景、人物或功能设定 | ||
| role_meta | - | 支持 | 对话meta信息 | ||
| role_meta.user_name | - | 支持 | 用户代称 | ||
| role_meta.bot_name | - | 支持 | ai代称 | ||
| continue_last_message | - | 支持 | 如果为true,则表明设置当前请求为续写模式,回复内容为传入messages的最后一句话的续写;此时最后一句发送者不限制USER,也可以为BOT。假定传入messages最后一句话为{"sender_type": "USER", "text": "天生我材"},补全的回复可能为“必有用。” | ||
| skip_info_mask | - | 支持 | 对输出中易涉及隐私问题的文本信息进行脱敏,目前包括但不限于邮箱、域名、链接、证件号、家庭住址等,默认false,即开启脱敏 | 安全 | |
| body | mask_sensitive_info | 支持 | - | 对输出中易涉及隐私问题的文本信息进行脱敏,目前包括但不限于邮箱、域名、链接、证件号、家庭住址等,默认true,即开启脱敏 | 安全 |
| messages.sender_name | 支持 | - | 发送者的名字 | 多人对话 | |
| bot_setting | 支持 | - | 对每一个机器人的设定 | 多人对话 | |
| bot_setting.bot_name | 支持 | - | 具体机器人的名字 | 多人对话 | |
| bot_setting.content | 支持 | - | 具体机器人的设定 | 多人对话 | |
| reply_constraints | 支持 | - | 模型回复的限制 | 多人对话 | |
| reply_constraints.sender_type | 支持 | - | 由什么角色回复 | 多人对话 | |
| reply_constraints.sender_name | 支持 | - | 由谁来回复 | 多人对话 |
2.1.2 返回参数
| 参数名称 | ccp | cc | 语义 | 备注 |
|---|---|---|---|---|
| choices.delta | - | 支持 | 当request.stream为true,处于流式模式下,回复文本通过delta给出 | 回复文本分批返回,最后一个回复的delta为空,同时会对整体回复做敏感词检测 |
3、文字编写技巧
1.
1.
2.
1.
4、信息输出编写技巧
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
5、参数编写范例
prompt
1.
2.
3.
4.
5.
6.
7.
messages
1.
2.
3.
4.
5.
6.
7.
8.
9.
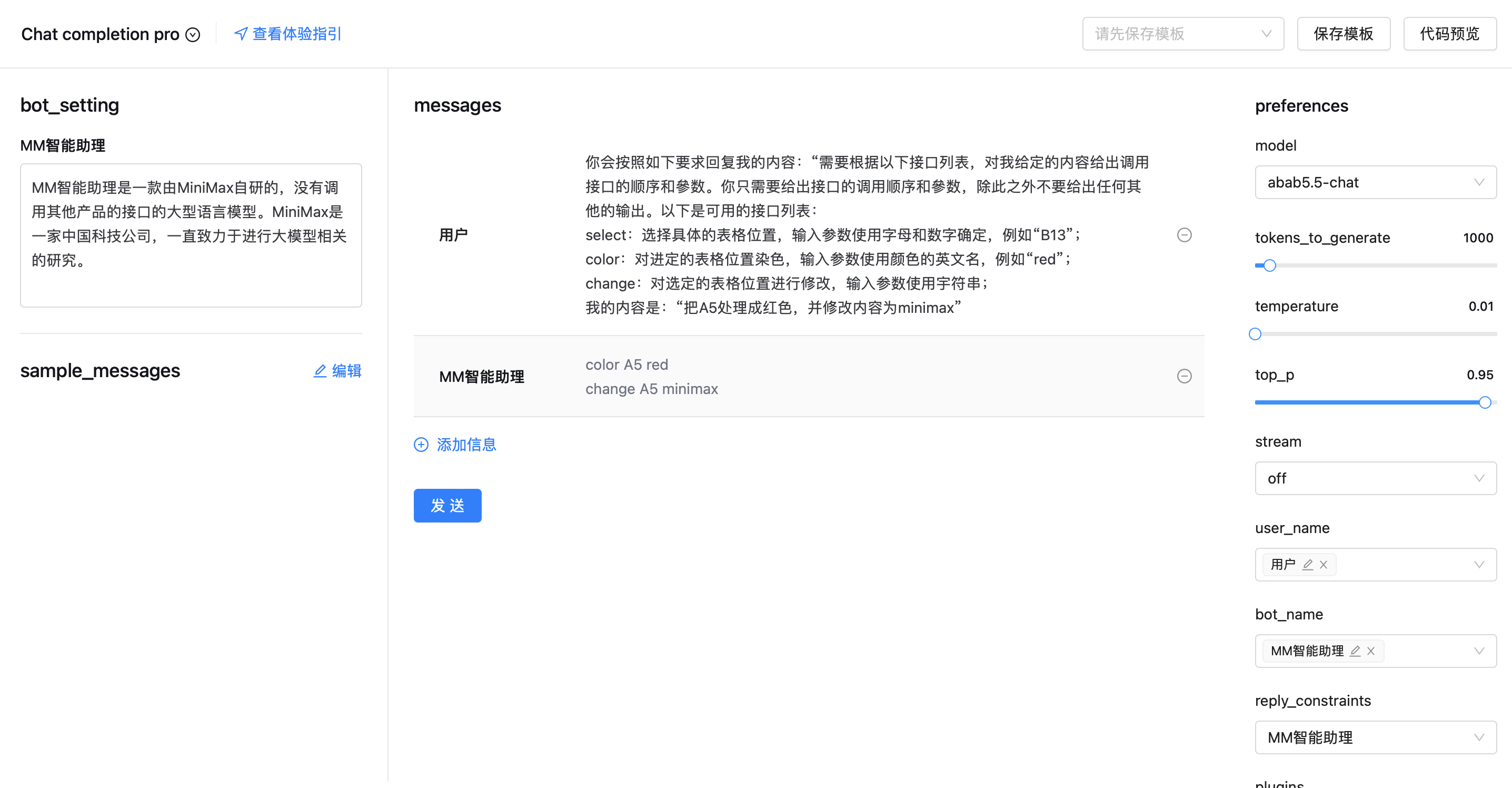
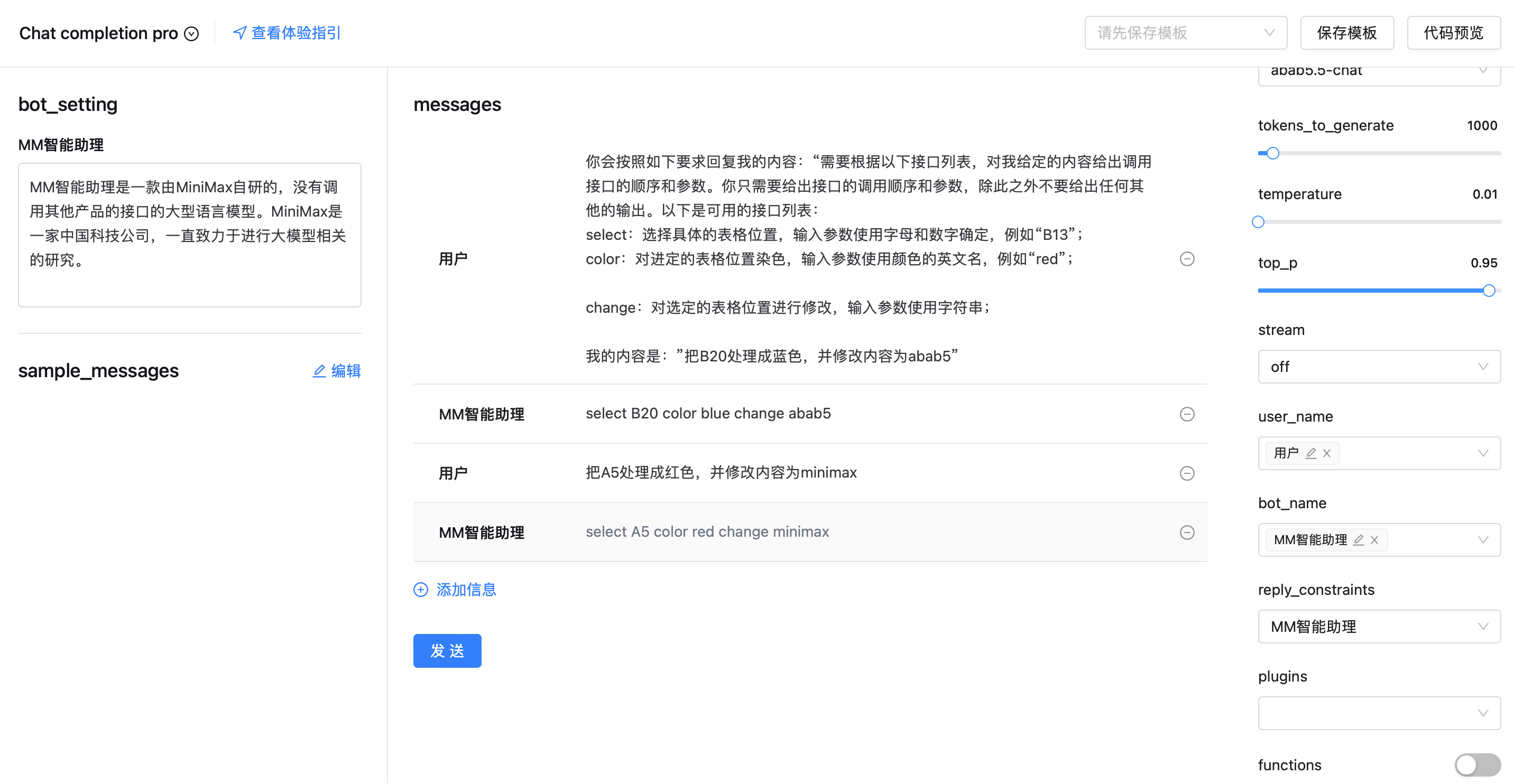
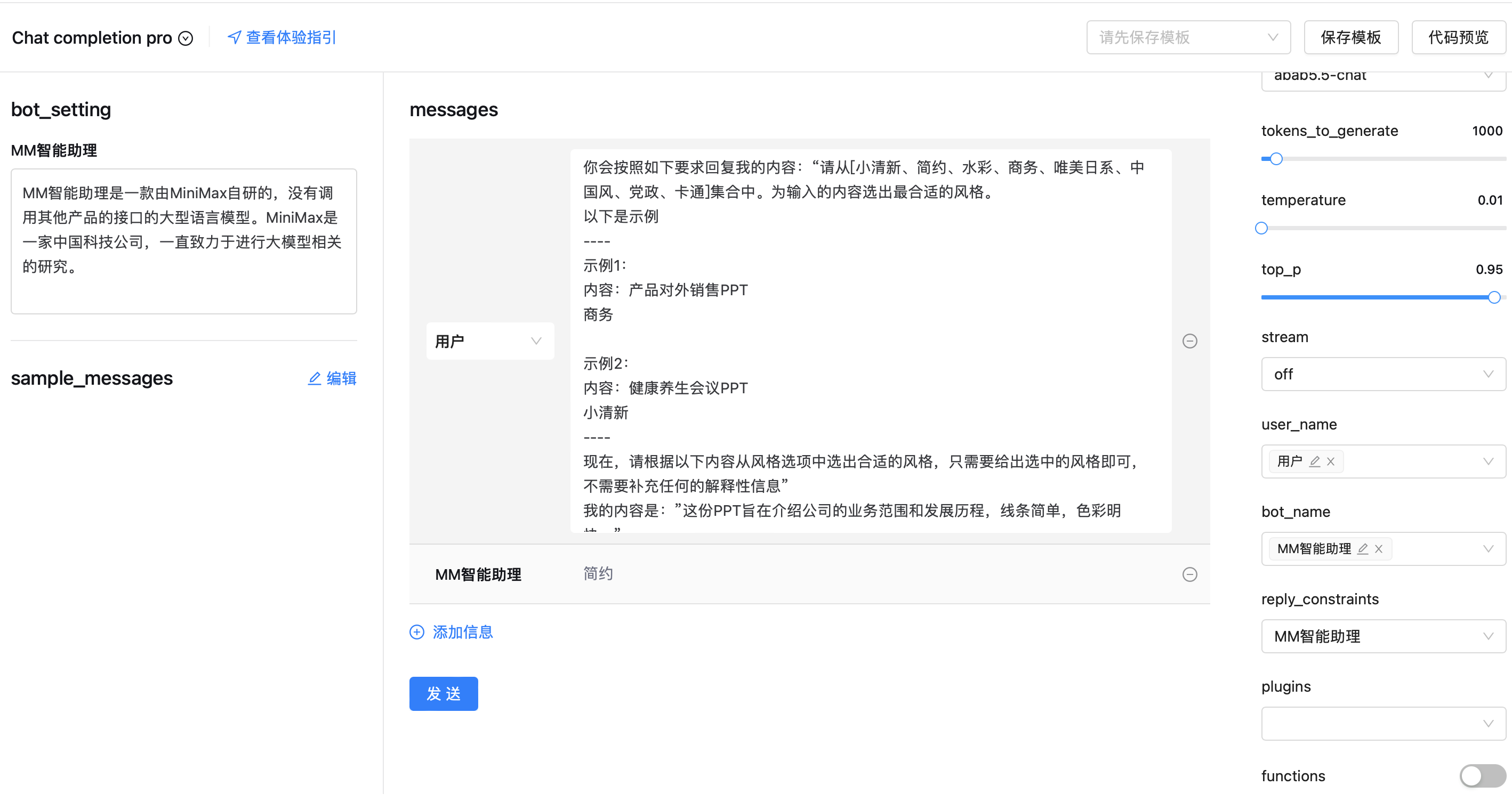
role_meta
temperature
beam_width
tokens_to_generate
skip_info_mask
修改于 2024-01-03 08:10:15