大模型介绍
复制页面
MiniMax
公告通知
产品定价
概述
FAQ
大模型介绍
文本大模型
语音大模型
接入说明
新手指南
速率说明
开发指南
快速开始
文本大模型接口
ChatCompletion Pro(对话)
概述
ChatCompletion Pro API 文档
ChatCompletion Pro API
示例对话功能
限制返回格式功能(glyph)
函数调用功能(function calling)
插件功能(plugins)
知识库检索功能(retrieval)
ChatCompletion(对话)
概述
ChatCompletion 快速接入
ChatCompletion 调优指南
ChatCompletion API 文档
ChatCompletion API
知识库检索功能(retrieval)
Assistants 接口
Assistants 操作指南
Assistans API 文档
Assistant
创建 Assistant
检索 Assistants
删除 assistant
查看 assistant 列表
Assistant File
创建 assistant 文件
检索 assistant 关联的文件
列出 assistant 文件
Thread
创建 thread
检索 thread
Message
创建 message
检索 message
message 列表
Run
创建 run
检索 run
列表 run
Submit tool outputs to run
Run Step
检索 run step
列表 run step
File(文档)
File(文档)
GET
Upload 接口
GET
Retrieve 接口
GET
Delete 接口
POST
RetrieveContent 接口
GET
Retrieval(知识库检索)
新建知识库
POST
删除知识库
POST
查看知识库详情
GET
查看知识库列表
GET
增加知识库文档
POST
删除知识库文档
POST
修改知识库文档
POST
查看知识库文档
GET
检索 Chatcompletion
POST
检索 Chatcompletion pro
POST
微调
Finetune 操作指南
Finetune API文档
创建微调任务
列出微调任务
检索微调任务
删除微调任务
列出微调事件
列举微调模型
查询微调模型
删除微调模型
向量化
Embeddings(向量化)
语音大模型接口
T2A (语音生成)
T2A 快速接入
T2A API 接口
T2A API接口
字典功能(Dictionary)
T2A pro(长文本语音生成)
T2A Pro 快速接入
T2A Pro API 接口
字典功能(Dictionary)
T2A large(异步超长文本语音生成)
T2A Large 快速接入
T2A Large API 接口
T2A Large API 接口
字典功能(Dictionary)
T2A Stream(流式语音生成)
T2A Stream(流式语音生成)
字典功能(Dictionary)
快速复刻(Voice Cloning)
上传文件
音频复刻
有声内容创作
Role Classification (文本角色分类)
创建并异步运行角色识别任务
查询角色识别任务
Role Audio Generation (角色音频生成)
角色音频生成
大模型介绍
复制页面
语音大模型
1、MiniMax语音模型介绍
#
MiniMax语音模型基于MiniMax自研多模态大模型底座,能够根据上下文,智能预测文本的情绪、语调等信息,进而生成超自然、高保真、个性化的语音,提供有丰富想象力并与文本匹配的声音表现。
1.1 传统语音合成行业的痛点
#
机械感强:牺牲部分人声的
自然度
,缺乏声音
情感化
表达
音色单一:生成音色的
可扩展性低
,难以满足不同场景的多样化需求
效率低下:复刻素材需要专业录音棚和设备,
成本高且耗时长
1.2 MiniMax语音模型的优势
#
依托新一代AI大模型能力,MiniMax语音模型能够根据上下文,智能预测文本的情绪、语调等信息,并生成超自然、高保真、个性化的语音。相较于传统语音合成技术,MiniMax的语音模型以更精准、快速的方式,在音质�、断句气口、韵律节奏等方面达到以“AI”乱真的合成新高度,为客户带来更生动、更具情感表现力的听觉体验。
高保真、超自然:具备理解人类语言中复杂含义的能力,包括情感、语气甚至笑声,从文本中预测喜悦、悲伤、愤怒等多维信息,生成更贴合“自然人声”的语音语调。在某些情境下,甚至能表现出极具戏剧化的特征,如发出笑声等
多样化、高延展:能在一定量的参数中学习到数千个声音的音色特征,并自由组合,生成无限数量的声音变体、情感和风格,无论是成熟御姐、温柔女主播,还是青涩男大、稳重男主持,亦或是其他风格化的音色,都能轻松生成,满足多元场景需求
低成本、高效率:无需专业录音环境和设备,我们的快速复刻服务可以在极简的条件下运行,只需提供30秒的录制音频,即可完成语音克隆。生成的语音与原音色高度相似,大幅减少时间和资金的投入
1.3 MiniMax语音模型能力说明
#
多维的音色能力
多语言:中文、英文、德文、法文等
多性格:可爱、温柔、干练等
多场景:新闻播报、语聊播客、有声读物、教育、IP复刻、数字人、CV配音、语音助手等
多元的产品服务
T2A(语音合成)接口:支持音量、语调、语速调整和混音功能
T2A pro(长文本语音合成)接口:在T2A接口的基础上,支持单次合成最高50000字符输入,支持比特率、采样率相关参数调整特性,支持音频时长、音频大小等返回参数,支持字幕返回
快速复刻服务:支持30秒音频复刻,生成接近复刻音色的语音
精品复刻服务:支持20分钟音频复刻,生成相同音色、口音、说话风格的语音
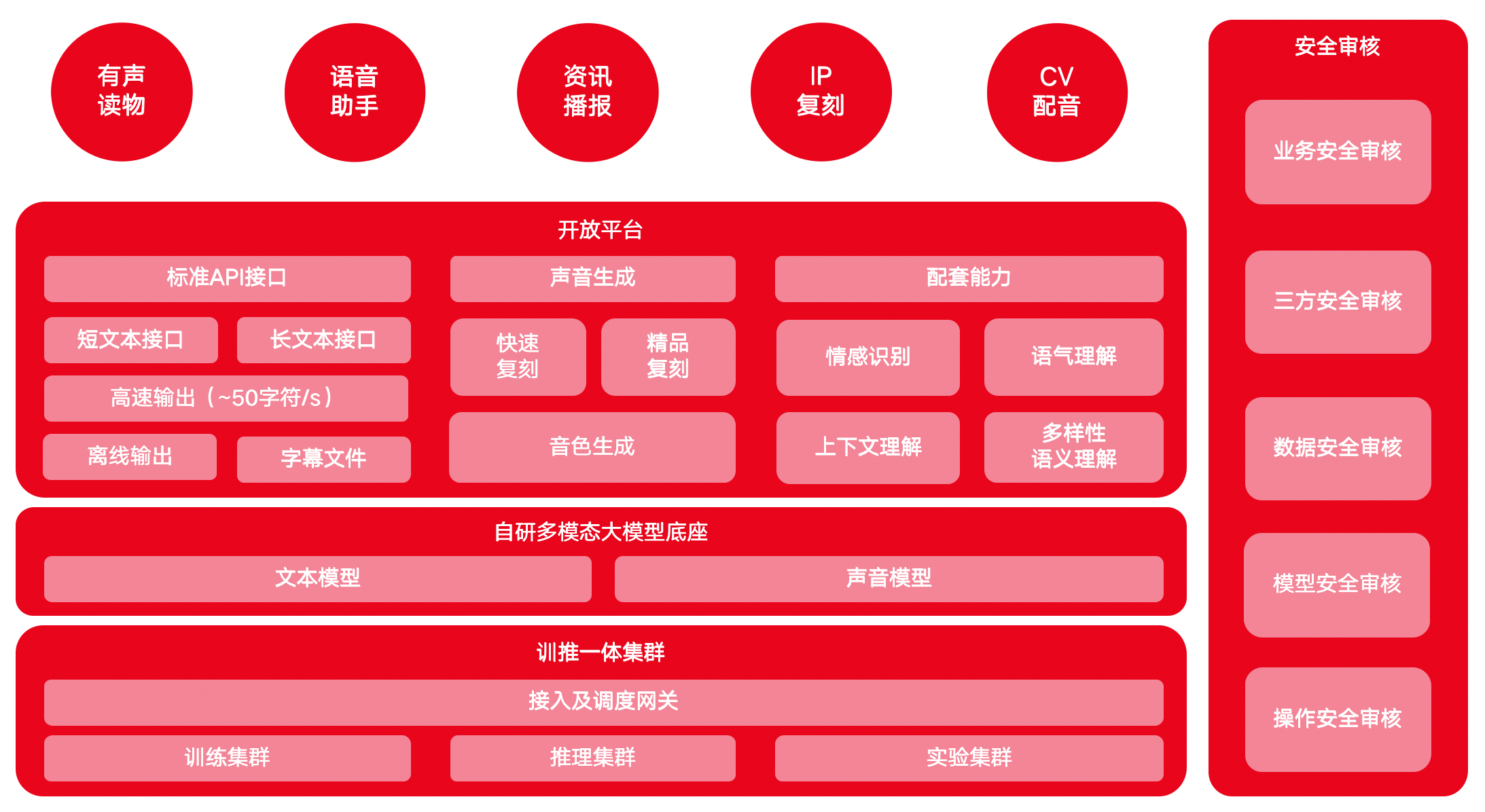
1.4 MiniMax语音大模型产品架构
#
2、价格及交付形态
#
价格
接口“T2A”和“T2A pro”,每10000字符10元。接口“T2A large”每10000字符2元
具体说明:收费模式以每10000个字符(输入)为基础计价单位。1个汉字算2个字符,英文字母、希腊字母、标点符号、特殊符号、空格、回车等为1个字符
详细定价文档:
https://api.minimax.chat/document/price?id=6433f32294878d408fc8293e
多元的产品服务
T2A(语音合成)接口
:支持音量、语调、语速调整和混音功能,多适用于语聊、社交、虚拟人、直播、游戏角色语音合成等短文本合成的相关场景
T2A pro(长文本语音合成)接口
:在T2A接口的基础上,支持单次合成最高50000字符输入,支持比特率、采样率相关参数调整特性,支持音频时长、音频大小等返回参数,支持字幕返回,多适用于新闻资讯播报、章节文字生成、有声书章节语音合成、教师逐字稿播读等相关场景
T2A large(异步超长文本语音合成)接口
:在T2A接口的基础上,支持单次合成最高1000万字符输入,支持非法字符检测等功能,适用于整本书籍语音合成的超长文本场景
多样的交付形态
公有云API:通过API调用标准化基座大模型,并根据模型处理字符数量计费
独占云端算力:可根据需求微调定制企业专属模型,并保障使用过程中的并发
云端私有化:在独占算力的基础上增加对于数据的安全性保障与云厂商背书的安全机制
本地私有化:基于自有算力的私有化部署方式,可确保数据不出域,模型私有化
进入“语音体验中心”,即可享受
22种
各具风格的音色体验,语音体验中心:
https://api.minimax.chat/examination-center/voice-experience-center
3、概念说明
#
3.1 音色克隆
#
区别于传统TTS语音音色克隆的高失真、生硬、工期长、效果不达标等特质,基于大语言模型的音色克隆更加精准快速,无需数小时时长的超高质量原音频、无需传统TTS的超长工期,可以在极短时间内完成音色复刻,并通过大语言模型加持,使复刻后的音色与原音色进行高质量还原,从而满足客户需求。
3.2 快速复刻(Fast clone)
#
至少30s音频,可以不同说话人,模型会对说话人风格进行融合
安静环境下录制,无背景噪声或有轻微背景噪声,无明显回声混响,信噪比没有具体要求,最好大于30dB
单声道,无压缩PCM WAV格式,24000以上采样率,16bit以上位深度,
可以生成和复刻音色相同的音色,但有些口音可能无法复刻的很好。
3.3 精品复刻(HiFi clone)
#
同一说话人至少20分钟音频
最好是专业录制设备在录音棚录制,无背景噪声,无回声混响,信噪比大于40dB
录音条件为在录音状态下的正式录音,保证平稳完整输出频率
录音文件要包含录制者习惯或需要的气口、情绪起伏及长段文字播读
录音时保证话筒或录制设备与播讲人保持的距离尽量一致,防止因声音忽大忽小影响复刻效果
单声道,无压缩PCM WAV格式,44100以上采样率,16bit以上位深度
可以生成和复刻音色相同的音色,口音,说话风格。人耳基本无法区分。
修改于
2026-06-07 08:05:20
上一页
文本大模型
下一页
新手指南